
The ability to gather and analyze data from the web is invaluable, and understanding the distinction of web crawling vs web scraping is essential for anyone looking to leverage this capability. This guide aims to clarify the differences and uses of these two fundamental techniques. The goal is to help you decide when and how to employ each effectively.
Briefly, web crawling involves navigating the web to index and map content systematically, while web scraping focuses on extracting specific data from web pages. By grasping these differences, you can optimize data gathering methods for your projects, whether for analysis, content aggregation, or beyond.
Table of Contents
Web Crawling vs Web Scraping: Definitions
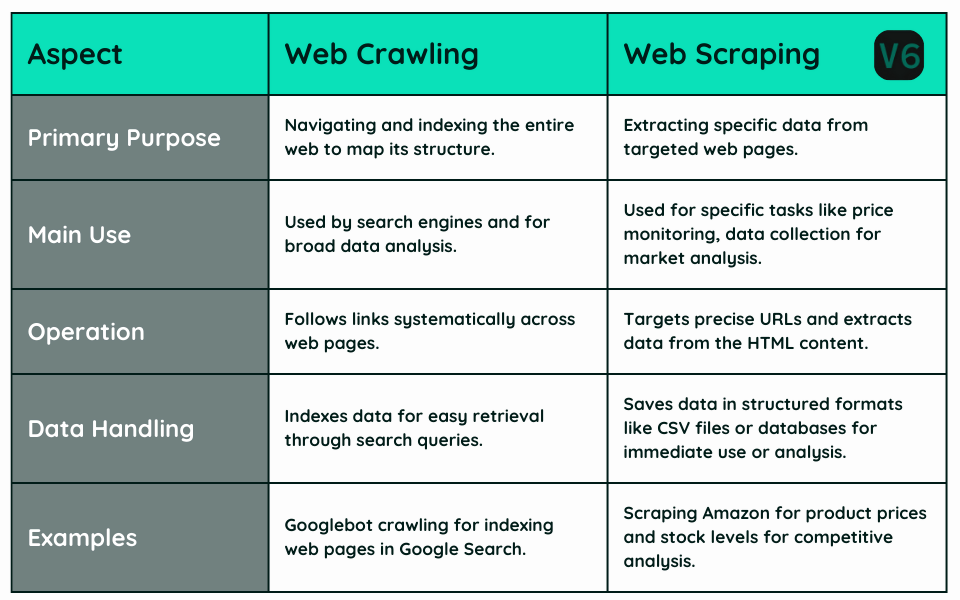
Web Crawling is a technique used primarily by search engines and large data analysis firms to systematically browse the internet and index content. A web crawler, also known as a spider or a bot, follows links across the web, capturing information from every accessible webpage. Its primary goal is to understand the structure of the internet and keep the data up-to-date.
Web Scraping, on the other hand, is focused on extracting specific pieces of data from web pages. Utilizing scrapers, which are scripts or software designed for this purpose, it targets precise information such as product prices, stock levels, text, and more. Web scraping is especially useful for collecting structured data from websites and transforming it into usable, actionable information.
Crawlers vs Scrapers: Specific Roles and Functionalities
Crawlers are designed to map the web extensively. They work by visiting web pages, reading the information on those pages, and following links to other pages. Their main tasks include:
- Navigation: They visit web pages systematically, reading and indexing the content.
- Link Following: Crawlers explore the web by following links from one page to another, which helps in mapping the web’s structure.
This extensive mapping is vital for search engines to retrieve and rank relevant web pages in response to user queries. Additionally, crawlers perform automated maintenance tasks on websites, such as link checking and HTML code validation.
Scrapers, on the other hand, are focused on extracting specific data from web pages. Their functionalities are tailored to precise tasks:
- Data Extraction: They target particular information like flight prices, stock levels, user engagement data on Facebook, Amazon customer reviews, whatsapp web scraping, google results, or job data on linkedIn.
- Data Aggregation: Scrapers can gather and consolidate information from multiple sources, often used in rank tracking, market analysis or competitive research.

Operational Differences: How Crawlers and Scrapers Work
Crawlers operate on a large scale, using algorithms that instruct them to visit a vast number of web pages and follow links within those pages. Their operation can be broken down into three key phases:
- Discovery: Crawlers start with a set of known URLs and discover new pages from links found in the previously crawled content.
- Indexing: As they crawl, they index web content by storing information about the pages, which makes the content retrievable through search queries.
- Updating: They frequently revisit web pages to update their indexes with the most current information, ensuring the data remains relevant.
Scrapers, conversely, are more focused and interact with web pages differently:
- Targeting: Unlike crawlers, scrapers do not randomly browse the web but instead target specific URLs where the required data is known to reside.
- Extraction: They parse the HTML of the targeted web pages to retrieve specific data elements like text, images, or other structured data.
- Storage: The extracted data is often saved in a structured format suitable for further analysis or immediate use, such as CSV files or databases.
While both crawlers and scrapers retrieve data from the web, they do so with different methods and objectives.
Use Cases and Applications
Choosing the right technique -crawling or scraping- depends heavily on the specific needs of a project or scenario. Here’s how to decide which to use:
When to Use Web Crawling:
- Search Engine Indexing: For building or updating a search engine’s database, crawling is essential to navigate through vast amounts of web pages to collect and index content.
- Content Monitoring: Organizations use crawlers to monitor changes across different websites, helping track updates or compliance with regulations.
- SEO Analysis: Crawlers can help in analyzing the SEO structure of a website, checking for broken links, and understanding site architecture to optimize search engine rankings.
When to Use Web Scraping:
- Competitive Pricing: E-commerce businesses often scrape competitor websites for pricing, product descriptions, and stock availability to stay competitive in the market.
- Social Media Analysis: Scrapers help extract specific data from social media platforms, like user comments and engagement rates, to tailor marketing strategies.
- Lead Generation: In sectors like real estate or recruitment, scraping tools gather contact information, listings, and job postings quickly and efficiently.
Scenario-Based Decision Making:
- Broad Data Collection vs. Specific Data Needs: Choose crawling when the goal is broad, such as understanding an entire website or a large dataset. Opt for scraping when you need specific pieces of data from particular pages.
- Ongoing Monitoring vs. One-Time Extraction: If the requirement is to keep a continuous check on a website for changes, crawling is more suitable. For one-time or periodic data extraction tasks, scraping is the better choice.
Related: What Is Screen Scraping Compared To Web Scraping?
Combining Crawling and Scraping
Combining web crawling and web scraping can provide a comprehensive data collection strategy that leverages the strengths of both techniques. Here’s how these methods can work in tandem and what challenges might arise.
Synergies of Combining Crawling and Scraping:
- Enhanced Data Collection: Use crawlers to map out a website or even multiple websites to identify where valuable data resides. Then deploy scraping to extract this specific data. This combination ensures thorough coverage and precise extraction.
- Dynamic Data Monitoring: Crawling can detect changes or updates in content across a broad range of pages, triggering scrapers to extract new data as it becomes available. This is particularly useful for keeping datasets up-to-date in real-time.
- Scalability and Efficiency: Crawlers can be used to pre-filter the content, determining the relevance or changes before scrapers are activated. This reduces the workload on scrapers and focuses their efforts, making the process more efficient.
Challenges of Using Crawling and Scraping Together:
- Technical Complexity: Integrating crawlers and scrapers requires a sophisticated coordination system that can handle scheduling, error handling, and data integrity checks. The setup and maintenance of such systems can be complex and resource-intensive.
- Legal and Compliance Risks: Combining both techniques increases the potential for legal challenges. This risk increases if the data collection spans multiple jurisdictions with different laws regarding automated data collection.
- Resource Management: Both crawling and scraping are resource-intensive in terms of network and computational power, especially when scaled up. Effective resource management and possibly substantial infrastructure investment are required to run both smoothly.
Best Practices for Integration:
- Clear Objectives: Define clear goals for what you need to achieve with both crawling and scraping. This clarity will guide the design of how both techniques should interact.
- Robust Infrastructure: Ensure that you have robust infrastructure capable of handling large-scale crawling and scraping operations. This includes adequate server capacity and rate-limiting capabilities.
- Compliance Strategy: Always stay informed about legal standards and ensure that your crawling and scraping practices comply with them.
Main Takeaways
- Web crawling and web scraping are two distinct data gathering techniques: crawling systematically navigates and indexes the internet, while scraping extracts specific data from web pages for targeted use.
- Crawlers, or spiders, are used mainly by search engines to map and update the structure of the web, capturing information from every accessible webpage, which is essential for retrieving and ranking pages in search results.
- Scrapers focus on pulling precise pieces of information from web pages, such as product prices or stock levels, and are particularly valuable for tasks like competitive pricing analysis or gathering data from social media platforms.
- Deciding between web crawling and web scraping depends on the project needs; crawling is suited for broad, continuous data collection across many pages, while scraping is ideal for obtaining specific data from targeted sources.
- Combining both crawling and scraping can enhance data collection by mapping out relevant data locations with crawlers and then extracting specific data with scrapers, though this approach requires sophisticated technical coordination and careful management of legal and resource challenges.
Related:



