Data parsing involves the process of taking input data in one form and transforming it into a more usable format. In the context of software development and data analysis, parsing is crucial as it allows for the automation of data processing, making data easier to understand and manipulate. In web scraping, parsing is essential for extracting data from web pages and converting it into structured formats that are useful for analysis and storage.
Table of Contents
What We Will Cover
Our goal is to clarify what it means to parse data by:
- Explaining the fundamental concepts of data parsing.
- Discussing its applications in software development and data analysis.
- Exploring the role of parsing in web scraping.
In previous articles, we covered:
- Instagram Scraping,
- Facebook Scraping,
- WhatsApp Scraping,
- Google Search Scraping With Python, other methods for SERP Scraping,
- LinkedIn Scraping,
- Amazon Scraping,
- Web Scraping Proxies,
- Scraping Cookies,
- Facebook session Expired Issue,
- And Web scraping vs Screen scraping.
Today: It’s the data parsing full guide you need.
What Is Data Parsing?
Data parsing is the process of converting data from one format to another by following a set of predefined rules or algorithms. This involves reading the input data, processing it, and producing output in a new format that is easier to access and manipulate.
In addition to its role in web scraping (which we will cover in detail), data parsing general applications include:
- In software development, parsing enables developers to create applications that can automatically interpret and use information from various data sources, such as databases, text files, or live data feeds. It is fundamental in scenarios where data integration and synchronization between different systems are required.
- In data analysis, parsing is essential for preprocessing data—transforming raw data into a clean dataset ready for analysis. This step ensures that data analysts and scientists can focus on deriving insights rather than spending time cleaning and organizing data.
Components and Types of Data Parsing
Understanding data parsing requires familiarity with its key components and the various methods available for parsing data. Each component plays a crucial role in the transformation process, while the different methods cater to specific needs and scenarios.
Components of Data Parsing
Before discussing the types of data parsing, let’s break down the core components involved in the process:
- Input Data: This is the raw data that needs parsing. It can come in many forms, from structured formats like CSV files to unstructured formats like HTML pages.
- Parsing Engine: The parsing engine is the algorithm or software that performs the parsing. It applies a set of rules to interpret the input data’s structure and content.
- Output Format: After processing the data, the parsing engine outputs it in a new, structured format, such as JSON or XML, that is suitable for further use or analysis.
Each component must work seamlessly to ensure the accurate and efficient conversion of data from its source form to the desired output format.

Types of Data Parsing
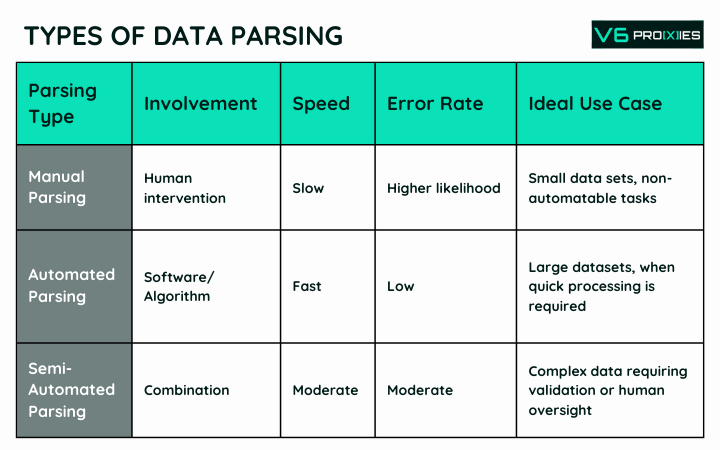
Different scenarios call for different parsing methods. Here’s a look at the primary types:
- Manual Parsing: Involves human intervention to interpret and convert data. This method is often slow and prone to errors but can be useful when dealing with small amounts of data or when automated parsing is not feasible.
- Automated Parsing: Uses software or algorithms to parse data without human intervention. Automated parsing is fast and consistent, ideal for large datasets and situations where speed is of the essence.
- Semi-Automated Parsing: Combines automated parsing with manual checks or interventions. This approach is effective when automated parsing requires additional validation or when dealing with complex data that may not be entirely suitable for fully automated parsing.
Each type of parsing has its place in data processing. The choice depends on factors such as data volume, complexity, accuracy requirements, and available resources.
What Does It Mean to Parse Data? (Process and Steps)
Parsing data isn’t just about converting it from one form to another; it’s about making the data understandable and usable by machines. Now, let’s delve into the step-by-step process that encapsulates what it means to parse data.
Detailed Process of Data Parsing
The parsing process can be complex, but it typically follows these fundamental steps:
1. Identification of Data Format:
It begins with identifying the format of the input data. Whether it’s text, audio, or video, understanding the format is key to determining the parsing technique to use.
2. Selection of a Parsing Technique:
Depending on the data’s format and the desired output, you select a parsing method. This could be syntactic parsing for structured data or semantic parsing when the context is important.
3. Lexical Analysis:
The parser breaks down the data into tokens, which are the smallest units that carry meaning, like words in a sentence or entries in a CSV file.
4. Syntax Analysis:
The parser then analyzes the tokens’ syntactic structure according to the rules of the data’s format, similar to understanding grammar in a language.
5. Semantic Analysis:
This step involves interpreting the meaning behind the tokens. In data parsing, it’s about understanding the context and purpose of the data.
6. Transformation:
Here, the parser begins to convert the data into the target format, which will be structured to fit the requirements of the receiving system.
7. Validation:
The parsed data is validated to ensure it meets quality standards and aligns with the target format’s schema.
8. Output Generation:
Finally, the parser outputs the data in the new format, ready for use in databases, applications, or other systems.
9. Review and Debugging:
If issues arise, a review and debugging phase may follow, where the output is checked for errors, and the parsing rules are refined for accuracy.
This detailed parsing process ensures data is accurately translated and can be relied upon in various applications, from powering a web application to fueling complex data analysis.

Tools and Technologies Used in Data Parsing
Parsing data effectively requires the right tools and technologies. Each tool or language has its own strengths, making it suitable for different types of parsing tasks. Let’s explore some of the common tools and programming languages used in data parsing.
1. Python
Python is renowned for its simplicity and readability, which makes it one of the most popular languages for data parsing. Libraries such as BeautifulSoup for HTML parsing and Pandas for CSV and Excel files simplify the process of reading and transforming data. BeautifulSoup, in particular, is a go-to for web scraping, allowing the extraction of data from HTML and XML files. Meanwhile, Pandas provides powerful data structures and functions to manipulate tabular data efficiently.
2. JavaScript
JavaScript, particularly when running on Node.js, is another versatile language for parsing data. With its non-blocking I/O model, it can handle large volumes of data without compromising performance. Tools like Cheerio provide jQuery-like syntax for navigating the DOM and manipulating data, which is invaluable for web scraping and server-side data parsing tasks.
3. XML Parsers
XML parsers are specialized tools designed to parse XML documents. They come in various forms, including SAX (Simple API for XML) and DOM (Document Object Model) parsers. SAX is event-driven and reads the document sequentially, making it memory-efficient for large documents. In contrast, DOM parsers load the entire document into memory, allowing for random access to the document’s elements, which can be more convenient but less memory-efficient.
4. JSON Parsers
JSON (JavaScript Object Notation) is a lightweight data-interchange format, and JSON parsers are essential for working with JSON data. Most programming languages provide built-in JSON parsing capabilities. For example, Python’s json module can parse JSON data from strings or files and convert them into Python dictionaries, making it easy to work with JSON in a Pythonic way.
5. CSV Parsers
CSV (Comma-Separated Values) files are a common format for tabular data, and CSV parsers are designed to handle them. Libraries like Python’s csv module and JavaScript’s PapaParse offer tools for reading and writing CSV files, handling the quirks of different CSV dialects, and providing a straightforward way to convert CSV data into arrays or other usable formats.
6. Custom Parsers
Sometimes, pre-built tools may not fit the specific needs of a project, especially when dealing with non-standard data formats. In such cases, custom parsers are written using programming languages to handle unique parsing requirements. This involves writing regular expressions or state machines that are tailor-made to interpret and transform the specific data format in question.
What Is Parsing In Web Scraping?
Data Parsing plays a pivotal role in web scraping, acting as the bridge between raw, unstructured web content and structured, actionable data.
It is about more than just sifting through HTML—it’s about unlocking the potential of the web as a data source. Despite the challenges, with the right techniques, it’s possible to extract valuable data from even the most complex of websites.
Role of Parsing in Web Scraping
In web scraping, parsing is the critical process of analyzing a web page’s content and extracting relevant information. It transforms the unstructured HTML code found in web pages into structured data, such as spreadsheets or databases. Parsing allows the scraper to identify and retrieve the specific pieces of data that are required from the vast and varied content of the web.
Challenges in Parsing Web Data
Web parsing comes with its unique set of challenges:
- Dynamic Content: Many modern websites load their content dynamically using JavaScript, which can make it challenging to extract data, as the content of interest may not be present in the initial HTML source.
- JavaScript Rendering: Web pages that rely heavily on JavaScript for rendering content require a parser that can execute JavaScript just like a browser, complicating the parsing process.
- Anti-Scraping Technologies: Websites may employ various techniques to detect and block scrapers, such as CAPTCHAs, IP rate limiting, or requiring cookies and session information for navigation.
Advanced Techniques
To overcome these challenges, sophisticated parsing techniques have been developed:
- Headless Browsers: Tools like Puppeteer or Selenium use headless browsers, which can render JavaScript and mimic human navigation patterns, enabling the scraping of dynamically loaded content.
- AJAX-loaded Data Management: Web scrapers can mimic the XMLHttpRequests (XHR) made by the page to fetch data via AJAX, allowing the scraper to retrieve the data directly from the source API or data stream.
- Rotating Proxies and User Agents: To avoid detection, scrapers can rotate through different IP addresses and user agent strings, making the requests appear to come from multiple users.
Glossary
- CSV (Comma-Separated Values): A file format used to store tabular data, such as spreadsheets or databases, where each row of the table is a text line, and columns are separated by commas.
- DOM (Document Object Model): A cross-platform and language-independent interface that treats an XML or HTML document as a tree structure wherein each node is an object representing a part of the document.
- HTML (Hypertext Markup Language): The standard markup language for documents designed to be displayed in a web browser. It can be assisted by technologies such as Cascading Style Sheets (CSS) and scripting languages such as JavaScript.
- JSON (JavaScript Object Notation): A lightweight data-interchange format that is easy for humans to read and write and easy for machines to parse and generate.
- Pandas: A software library written for the Python programming language for data manipulation and analysis. It offers data structures and operations for manipulating numerical tables and time series.
- Puppeteer: A Node library which provides a high-level API to control Chrome or Chromium over the DevTools Protocol. It is often used for automated testing of web pages, including rendering, user interactions, and other relevant tasks.

- SAX (Simple API for XML): A serial access parser API for XML. It processes the XML file sequentially, triggering events as it encounters opening tags, closing tags, text, etc.
- Selenium: An open-source umbrella project for a range of tools and libraries aimed at supporting browser automation, and is primarily used for automated web testing.
- Token: The smallest unit that carries meaning in a text. In parsing, it’s a significant element such as a word, phrase, or symbol identified by the parser.
- XML (eXtensible Markup Language): A markup language that defines a set of rules for encoding documents in a format that is both human-readable and machine-readable. It is often used for the representation of arbitrary data structures, such as those used in web services.
- XHR (XMLHttpRequest): An API in the form of an object whose methods transfer data between a web browser and a web server. The object can be used to retrieve data from a URL without having to do a full page refresh.